


描述
其他信息
描述
额外信息
| 型号 | 400G-QSFP-DD-LC-10KM |
|---|---|
| 系列 |
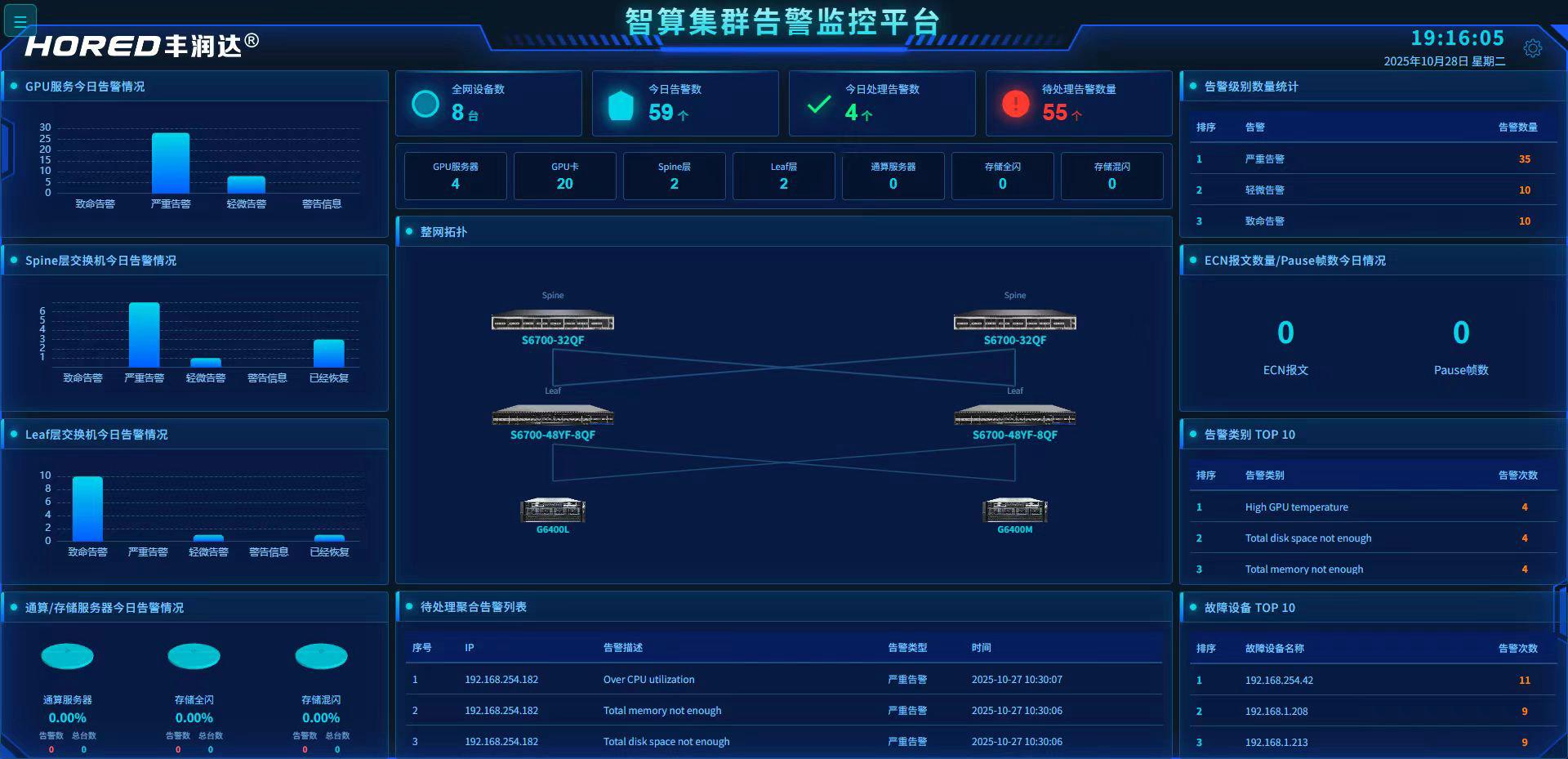
ROCE管理平台是构建高性能、智能化数据中心的神经中枢。它通过全面的可视性、自动化的运维流程和深度的分析洞察。平台提供集中化RDMA网络管理功能,支持管理授权,支持授权扩展与动态分配
软件功能说明:
平台提供集中化RDMA网络管理功能,支持管理授权,支持授权扩展与动态分配
一、自动化部署
– 支持交换机、主机的零接触自动上线;
– 模板化配置下发;
– 一键式智算中心网络初始化。
平台提供设备自动识别与配置向导功能,支持零接触部署(ZTP)。
提供主机侧agent,实现IP地址分配、RoCE参数配置自动化部署
二、全栈拓扑可视化
– 自动发现交换机—GPU—RoCE网卡拓扑;
– 支持链路状态高亮与错误连线定位;
– 自动识别GPU节点内部结构关系。
提供全栈拓扑可视化,自动识别交换机、GPU、RoCE网卡连接关系;支持链路错误检测与可视化告警。
三、智能健康检测
– 提供“训前健康检查”;
– 检测网络连通性、带宽、时延、GPU状态;
– 提前预警潜在风险并生成检测报告。
平台内置“训前健康检测”功能,对作业涉及的节点、网络链路、存储资源执行多维度检测
四、实时性能与流量监控
– 实时采集GPU间通信流量;
– 提供链路级性能监控;
– 可视化展示时延、丢包与PFC阻塞信息。
提供作业感知流量分析模块,实时监控GPU卡间流量与通信路径。
五、随流分析
– 基于作业流识别的实时路径追踪;
– 支持流量路径、时延、抖动、瓶颈定位;
– 关联作业ID生成可视化流量视图。
支持gRPC、NETCONF、SNMP、Telemetry等协议,全面采集物理层运行指标。
提供随流分析功能,对训练作业流进行路径追踪与性能检测。
六、开放集成
– 北向提供RESTful/gRPC API;
– 可与调度系统(Slurm/KubeFlow)集成;
– 支持第三方可视化平台(Grafana、Zabbix)接入。
七、统一设备管理优势
– 平台可统一管理交换机、光模块及服务器设备;
– 支持集中监控交换机配置、光模块状态及主机网卡运行参数;
– 提供统一的运维界面和权限系统,降低运维复杂度。
一、安全机制
– 支持HTTPS加密通信,防止传输数据泄露;
– 管理端与Agent间采用Token认证与白名单;
– 用户登录采用双因素认证;
– 所有管理操作均可审计。
二、权限与审计
– 多租户与角色访问控制;
– 操作日志集中存储与追溯;
– 系统审计报告导出功能。
三、可靠性与高可用设计
– 控制平面与数据采集平面分离;
– 双机热备与多节点冗余;
– 节点故障自动迁移;
– 集群状态实时同步。
四、容灾与备份
– 支持本地与远程容灾;
– 定期快照与一键恢复功能。
一、部署环境要求
推荐操作系统:Ubuntu Server 22.04 LTS
兼容版本:Ubuntu 20.04 / CentOS 7+
依赖组件:Docker、Kubernetes(可选)、Python 3.8+、gRPC 库、PostgreSQL
二、部署方式
– 虚拟化部署(VM或私有云);
– 容器化部署(Docker/K8s);
– 裸金属部署;
– 支持离线包安装与批量脚本安装。
三、部署架构逻辑
系统分为控制节点、采集节点、分析节点、可视化节点和Agent节点,各节点间通过加密通道通信,实现集中管理与高可用部署。
四、硬件与网络建议
CPU≥8核,内存≥32GB,SSD≥500GB,网络接口≥10GbE,GPU节点支持NVIDIA或昇腾,系统备份采用NFS或对象存储。
| 型号 | 400G-QSFP-DD-LC-10KM |
|---|---|
| 系列 |
还没有帐户? 免费注册
请输入你的用户名或电子邮件地址。 你会收到一个链接到创建一个新的密码通过电子邮件。 现在还记得吗? 返回登录
已经有一个帐户? 登录





